
If you’ve heard of data integration, you’ve probably heard of ETL and ELT.
Many organizations have several hundred (or even thousands) of data sources from all aspects of their operations – whether it be applications, sensors, IT infrastructure, or third-party partners.
ETL and ELT make these multiple data sources easier to manage by allowing data teams to transform each data source into easier-to-read chunks and transfer them from one database to another.
They don’t do this in the same way, though. Organizations often have to choose between ETL vs ELT to suit their specific data needs.
In this article, we’ll be exploring the key differences between ETL vs ELT to help you choose the best data integration approach for your business.

What is ETL (Extract, Transform, Load)?
ETL stands for Extract, Transform, Load. It's a fundamental process used in data integration that involves combining data from various sources into a single, consistent format for analysis.
ETL helps create a centralized view of data, making it easier to analyze trends, identify patterns, and gain valuable insights from your data assets. The method began in the 1970s and continues to be crucial for on-premise databases with finite memory and processing power.
ETL tools can handle structured data from databases, semi-structured data like JSON files, and even unstructured data from log files. This allows you to create a unified view of your data, eliminating silos and enabling comprehensive analysis.
They can handle a wide range of data sources and formats, too, and offer options for configuring transformation rules to meet your specific data needs. This flexibility makes ETL adaptable to various data management scenarios.
How does ETL Work?
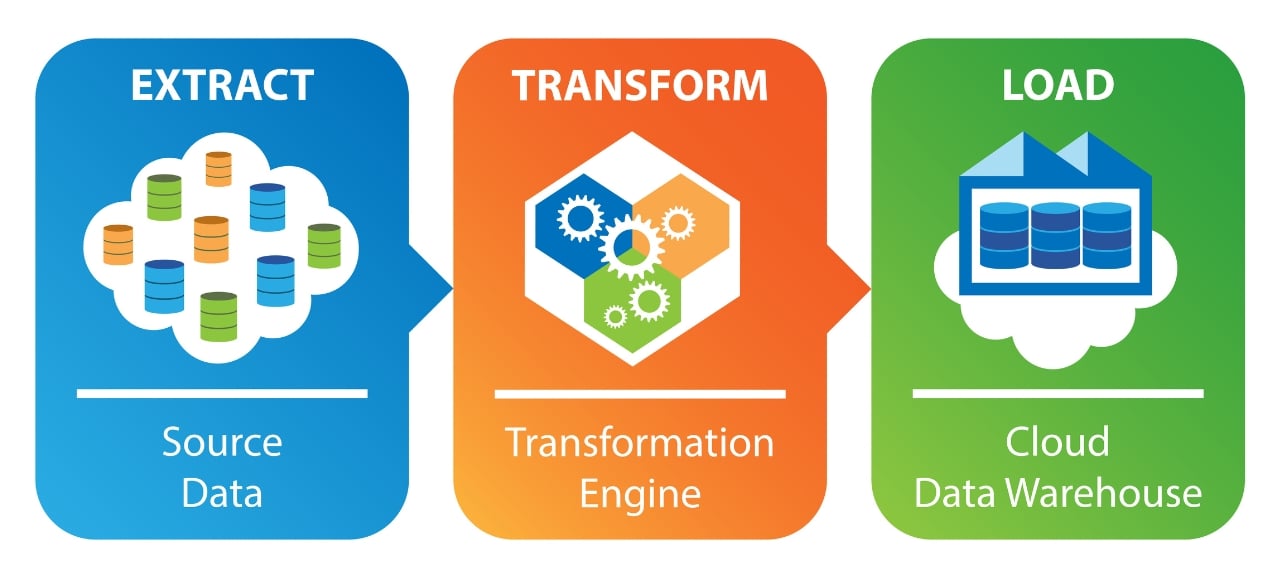
ETL processes clean and transform the data to ensure consistency and accuracy. This might involve fixing errors, formatting dates and currencies, or removing duplicates. Data is also often enriched once it’s combined with information from other sources.
The ETL process is split into 3 stages – Extract, Transform and Load:
1. Extract
In this stage, the ETL process up relevant data from various sources. These sources can be databases like customer info or sales figures, flat files like spreadsheets, or even application logs.
2. Transform
The extracted data might be messy or inconsistent. This is where the magic happens. The ETL process cleans the data, fixing errors, removing duplicates, and ensuring everything is formatted correctly. It's like sorting and prepping the data for analysis.
3. Load
Finally, the clean and transformed data is loaded into its destination, which could be a data warehouse for analysis or a data lake for raw storage. This is like putting all the prepped ingredients into a for the final dish.
ETL workflows are typically automated, allowing them to run on pre-defined schedules. This ensures data is consistently updated and minimizes manual intervention, saving time and resources.

Why CIOs Bet on Integrators
How top system integrators turn fragmented SaaS, legacy stacks, and IoT into a coherent platform for scalable digital operations.
What is ELT? (Extract, Load, Transform)
ELT stands for Extract, Load, Transform. It's a method used to move data from various sources to a central repository, like a data warehouse or data lake.
ELT is particularly useful for handling large datasets because loading raw data is generally faster than transforming it beforehand. Since the data structure isn't predetermined during the loading stage, ELT offers more flexibility when the data schema (organization) needs adjustments later.
Read: Top 10 Data Warehouse Tools for 2024
With the ELT data pipeline, data cleansing, enrichment, and data transformation all occur inside the data warehouse itself. Raw data is stored indefinitely in the data warehouse, allowing for multiple transformations.
Data lakes, the typical target system for ELT, are designed to handle evolving data structures. This means you can add new data sources or modify existing ones without needing major changes to the target system.
How does ELT work?
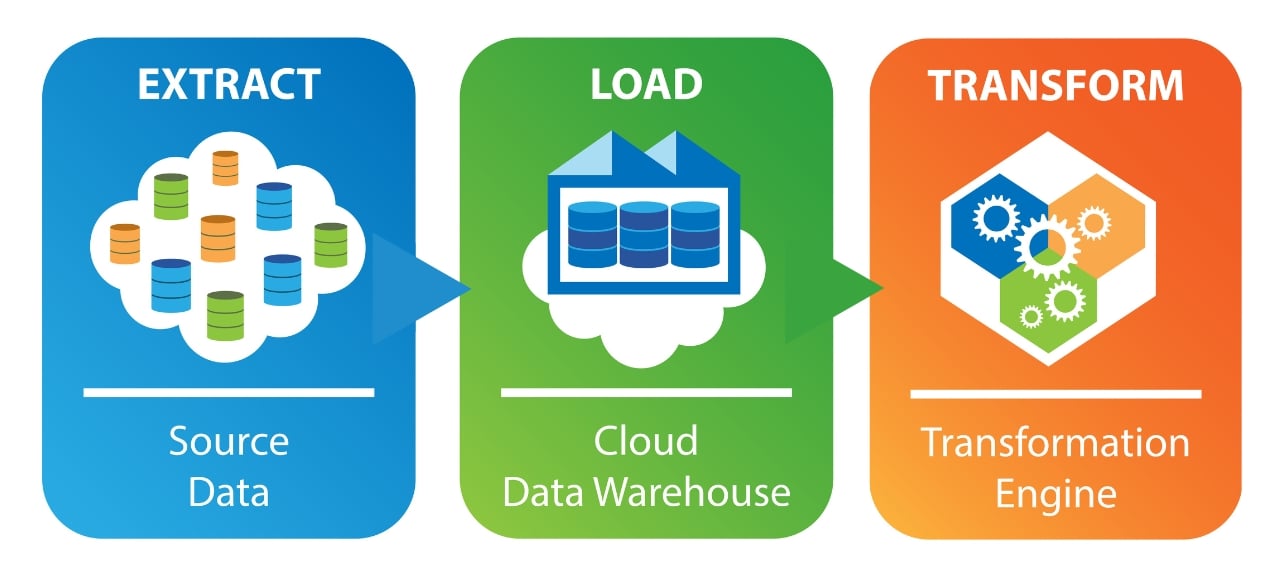
Like ETL, ELt involves moving data from various sources to a central location for analysis. But ELT loads raw data directly into a target data warehouse, instead of moving it to a processing server for transformation.
ELT is split into three stages – Extract, Load and Transform:
Inside Modern MDM Stack Design
Key capabilities leaders require from MDM platforms to unify CRMs, ERPs and legacy systems into a resilient data backbone.

1. Extract
Like in ETL, in ELT Data is first retrieved from its original source systems like databases or applications. This involves writing scripts or using tools to pull the data out.
2. Load
The extracted data is directly loaded into the target system, which can be a data warehouse or more commonly a data lake in ELT. Data lakes are massive repositories designed to store huge amounts of data in their raw format, including structured, semi-structured, and unstructured data.
3. Transform
Unlike ETL, where data is transformed before loading, with ELT the transformation happens within the target system itself after the data is loaded. This means the raw data is stored first. There are various tools and techniques for data transformation within the target system, depending on the specific platform being used.
ETL vs ELT: What’s the Difference?
The key difference between ETL and ELT is when the data is transformed. With ETL, the data is transformed before it’s loaded into the data warehouse. With ELT, however, data is extracted from its origins and loaded directly into the target system, and transformation happens after the data is loaded.
There are other differences, of course. For one, ETL requires a pre-defined schema for the target warehouse, which dictates the structure and format of the data before loading. ELT, however, Offers more flexibility in schema design. Data lakes can handle various data formats (structured, semi-structured, unstructured) without a rigid upfront schema definition.
ETL Can be slower when analyzing large datasets due to the upfront transformation step. ELT generally offers faster loading times than ELT, especially for big data, as raw data is loaded directly. Transformations can happen later in parallel.
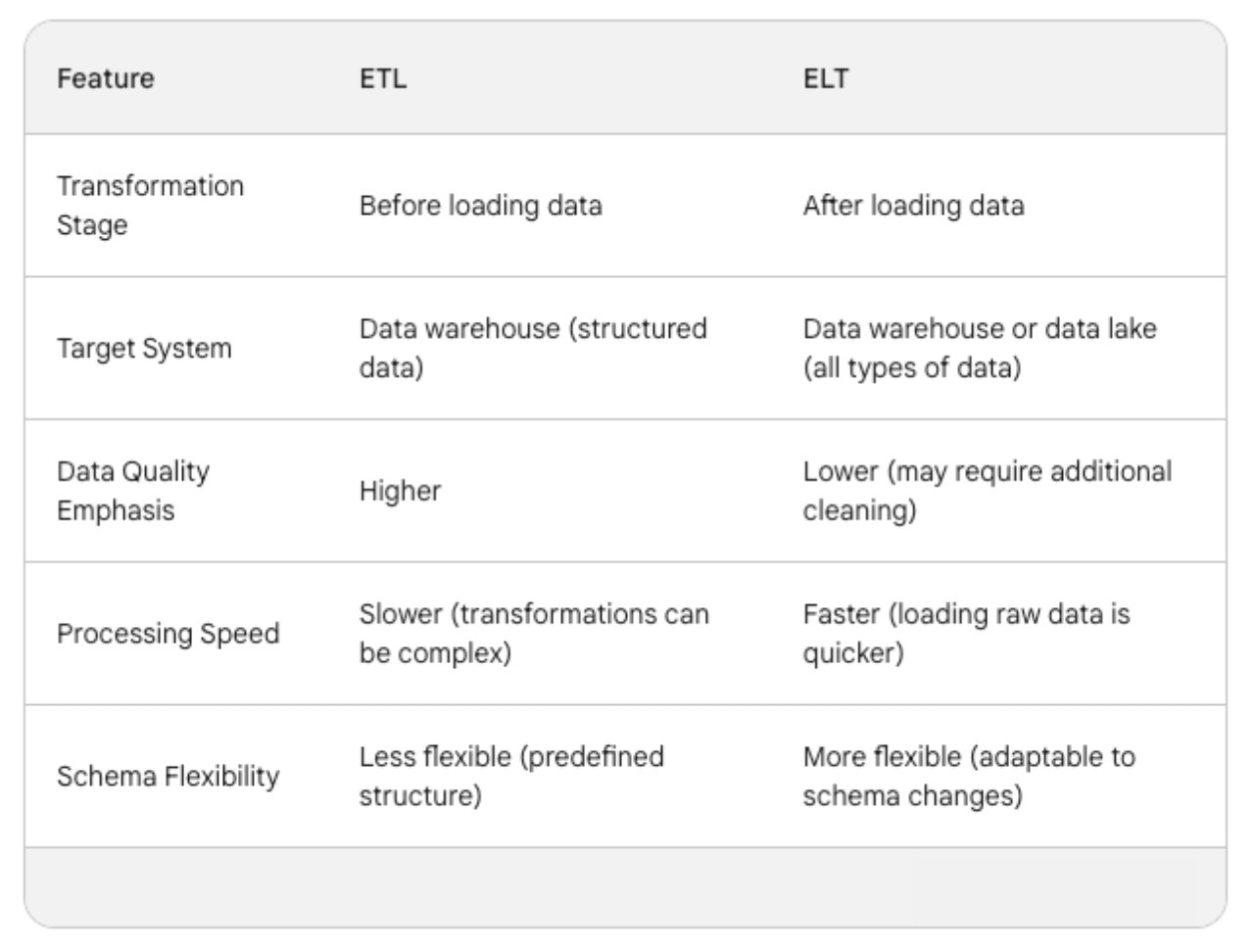
Here’s a table summarizing the key differences between ETL vs ELT:

When Fragmented Data Stalls
Disconnected systems hide risks, slow insight, and erode value. Integration aligns data to operations, compliance and growth.
ETL vs ELT: Key differences
1. Transformation Timing
- ETL: Performs data transformation before loading it into the target system (data warehouse). This ensures a clean and structured format that aligns with the warehouse schema.
- ELT: Loads data directly into the target system (often a data lake) and defers transformation until later. This allows for faster initial data ingestion.
2. Schema Definition
- ETL: Requires a pre-defined schema for the target warehouse, dictating the structure and format of the data before loading.
- ELT: Offers more flexibility in schema design. Data lakes can handle various data formats (structured, semi-structured, unstructured) without a rigid upfront schema definition.
3. Data Quality
- ETL: Emphasizes data quality by transforming and cleaning the data before it enters the warehouse, reducing inconsistencies and errors.
- ELT: May require additional cleaning after loading since initial data might contain inconsistencies. This can be addressed through data quality checks within the target system.
4. Processing Speed
- ETL: Can be slower for large datasets due to the upfront transformation step.
- ELT: Generally offers faster loading times, especially for big data, as raw data is loaded directly. Transformations can happen later in parallel.
ONA: Rethinking Internal Networks
Use organizational network analysis to turn informal relationships into a blueprint for faster decisions and more effective collaboration.

5. Query Speed
- ETL: Often enables faster queries because the data is already transformed and structured for analysis within the warehouse.
- ELT: Might have slower query speeds if transformations occur during the query process, putting strain on the target system's resources.
ETL vs ELT: Which should you choose?
Choosing between ETL and ELT depends on your specific data integration needs and priorities. If you’re looking for data quality, ETL’s upfront transformation may be better as it ensures lean and validated data entering the warehouse, reducing errors in analysis. But if speed and schema flexibility is your main concern, ELT may be the better choice.
Choose ETL if:
- Data Quality is important to you. ETL ensures data is cleaned and standardized before loading, reducing errors and inconsistencies in your analysis.
- You're working with smaller Datasets. ETL is often faster for smaller datasets because the transformation overhead isn't significant.
- You're looking for faster queries. Pre-processed data in ETL allows for quicker retrieval and analysis through optimized queries.
- You need a well-defined Schema: Choose ETL if you have a clear understanding of your data structure upfront and need it to fit a specific warehouse schema.
Choose ELT if:
- You're handling Big Data. ELT gets the data in quicker for initial exploration, making it great for dealing with massive datasets where faster loading times are crucial.
- You need a flexible schema. If your data structure might evolve over time, or you have various data formats (structured, semi-structured, unstructured) that a data lake can handle, go for ELT over ETL.
- Data Exploration is important to you. If you prioritize exploring and analyzing a wider variety of data formats before committing to specific transformations. ELT allows for more flexibility in this initial analysis phase.
Cloud-based data warehouses often favour ELT due to their scalability and ability to handle raw data transformations. But ETL might be preferred for sensitive data where upfront transformation and validation can enhance security measures.
The skills and experience of your data team can influence is key too, as ETL might require more expertise in data transformation tools than ELT.
Ultimately, the best approach depends on your specific context. It may be worth exploring hybrid solutions that incorporate elements of both ETL and ELT depending on your data pipelines.




Comments ( 0 )