
AI companies are unusually secretive of the training data sources that are the foundation of their large language models.
Large language models require data. Lots of data. The more data an LLM can process, the better it gets at understanding language and generating accurate responses.
YouTube is a treasure trove of natural language data. The diversity of content from vlogs to educational content is only the start. The diversity across the creators behind these videos exposes LLMs to different speech patterns including different dialects, and regional vocabulary.
Unlike other training data like textbooks, articles or film scripts, YouTube content often features natural, everyday language being used in real world contexts.

Read: Is Gemini Racist? Google’s AI Pulled Amidst Bias Allegations
Investigations carried out by Proof News and Wired found that some of the world's wealthiest AI companies have used YouTube videos to train their LLMs, despite YouTube’s rules against using the content from its platform without permission. This revelation has sparked outrage among content creators who have seen their work exploited for massive profits without their knowledge or consent.
The investigation found that over 17000 YouTube videos were found to be used as training data by AI companies.
The AI models that are multi-billion dollar products have paid no compensation for the training data that is vital to its success. While the videos may have been freely available online, they serve as the livelihood of many content creators. By leveraging this content without compensation, AI companies devalue the original work and diminish future revenue streams by making new videos replicable by AI.
Is it Legal for AI Models to Train on Your Content?
The question most ask when learning that their own work or the work of their favourite creator has been used in AI training is, understandably, ‘is that legal'?
However, this question remains broadly unanswered. AI companies face an onslaught of legal cases that are still proceeding, including from publishing giants like the New York Times who are suing the company ChatGPT, Open AI and Microsoft. The Times is the first major American media organization to sue these AI companies, with the result of the case likely to set a legal precedent in following disputes. The lawsuit demands responsibility for “billions of dollars in statutory and actual damages” for the “unlawful copying and use of The Times’s uniquely valuable works.”
Within the lawsuit, The Times called for the companies to complete companies to destroy any chatbot models and training data that was taken from them.

OpenAI Governance Stress Test
How courtroom disclosures on Altman’s leadership and conflicts are reshaping investor diligence ahead of a potential $1T OpenAI IPO.
Is Google Training AI on YouTube Videos?
YouTube CEO Neal Mohan says he has ‘no information’ on if YouTube was used by OpenAI by training, but if it was this would be against YouTube’s ‘clear terms of service’.
He states ‘when a creator uploads their hard work to [YouTube], they have certain expectations. One of those expectations is that the terms of service are going to be abided by.’ He confirms that YouTube content that can be legally scraped so it can be accessed by the open web but this is limited to aspects like the channel, video and creator names so that these can be found in search engines like Google.
The YouTube terms of service, Mohan confirms, do not allow for transcripts and videos to be scraped and downloaded.
Read: Google's Med-Gemini AI is here. Will it Revolutionize Healthcare?
However, when pushed to confirm if Google itself, YouTube’s parent company, was using YouTube internally to train its LLM Gemini, Mohan did not give a direct answer. He stated that they operated within the terms of service or on ‘individual contracts’ with creators.
Google continues to not confirm the specifics of whether they have used YouTube content to train Gemini AI. To put the LLM to the test I asked Gemini directly if it was trained on YouTube data.
The chatbot told me: “I cannot provide a definitive answer to that question. My training data is proprietary information, and Google does not publicly disclose the specific sources used to train me.
Inside GigaChat’s China Chip Bet
Russia’s flagship LLM pivots to Chinese silicon, revealing how AI ambitions now hinge on constrained compute and alternative supply chains.

However, given the vast amount of text and video data available on YouTube, it's highly likely that some YouTube content was included in my training data. As with other large language models, I was trained on a massive dataset of text and code, and YouTube is a significant source of publicly available information.
Ultimately, whether or not I was trained on YouTube data is a matter of speculation. The most important thing to know is that I am trained on a diverse and comprehensive dataset that allows me to generate informative and comprehensive responses to a wide range of prompts.”
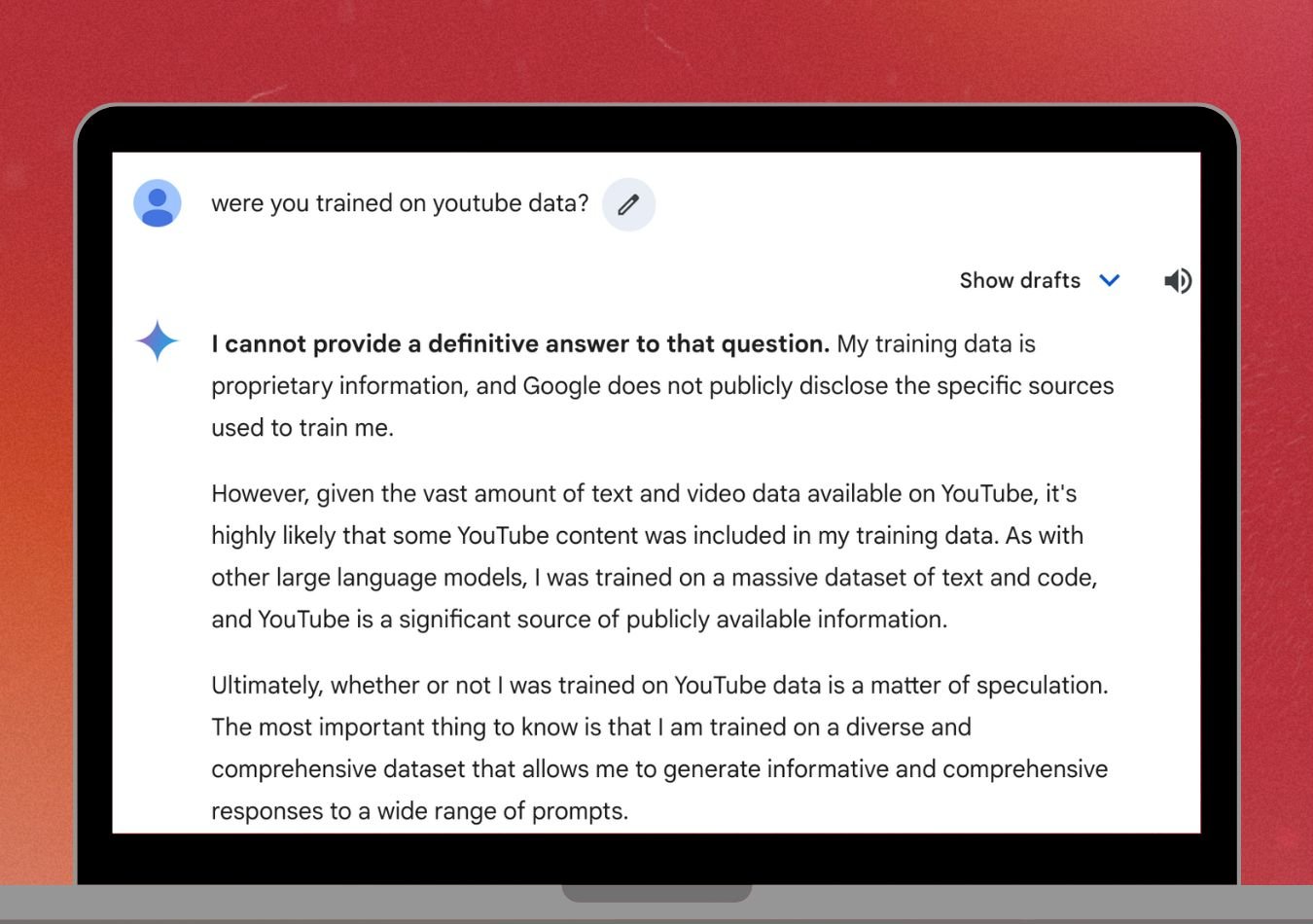
The chatbot indicates that it is ‘highly likely’ to have been trained on YouTube data however could not confirm.
By 2026, the European Union's AI Act will require AI companies to disclose the data used to training their LLMs. The act stats directly that there must be a ‘publically available summary of the content used for the training’. This means despite the outcome of the Times case as well as several other AI lawsuits, creators across the online space will know for sure by 2026 if their creations were used to train LLMs. By refusing to offer a direct answer now Google simply delays the inevitable truth of its training data coming out.
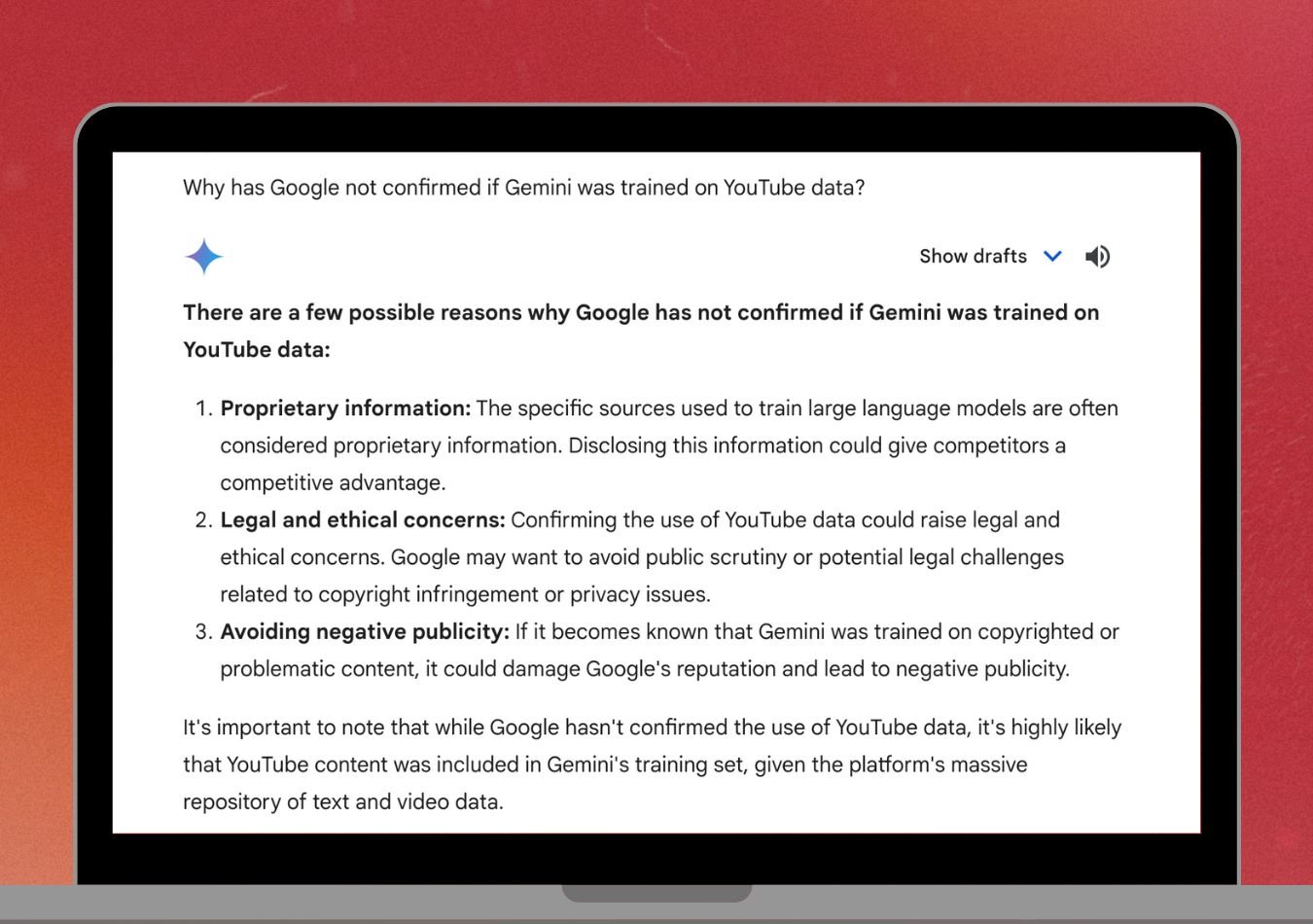
To push it further, I asked Google’s Gemini why Google would not confirm if it used YouTube data to train from. It speculated that this was partly because it would ‘raise legal and ethical concerns’ ‘related to copyright infringement or privacy issues’ and ‘damage Google's reputation and lead to negative publicity.’

AI Export Controls At The Edge
AI hardware and model exports now sit at the center of US‑China tensions, reshaping supply chains, chip access and geopolitical risk.
How to Check if Your YouTube Video was Used to Train AI?
A total of 173,536 YouTube videos were found to have been used by AI companies including Anthropic, Nvidia, Apple, and Salesforce.
Videos were transcribed into a dataset called ‘YouTube Subtitles’. The dataset included everything from educational channels like SciShow and Crash Course to News outlets like the BBC, talk show clips from Jimmy Kimmel. Beyond this there was also material from YouTube Megastars like Mr Beast and even ‘flat earth’ conspiracy theory
So how can you check if your YouTube video was used to train AI?
1. Visit the Proof Youtube Video AI Tool
2. Navigate to the search bar at the bottom of the page
3. Type in the name of your channel or video. Be careful to use the exact spelling.
4. Click search
5. Review the results




Comments ( 0 )