When judging the success of a machine learning (ML) model for making predictions, it can be difficult to differentiate between a good one and a bad one.
We can judge a model based on its output from a known data set, examining how well it performs, how accurate it is, or how many prediction errors it makes. But this does not tell us about how well it generalises new input data from sources beyond the data it’s trained on.
The challenge data scientists face is that some ML models may be able to give accurate predictions for training data but then fail to do so with new data.

This problem, known as overfitting, can make it difficult for data scientists to correctly estimate the success of the model they’re using, leading to problems later in the training process if they can’t detect it.
This article tells you everything you need to know about overfitting, including what it is, why it happens, and how you can detect and prevent it.
What is overfitting in machine learning?
Overfitting is a problem that occurs when a machine learning model becomes too closely adapted to the data it's trained on. This leads to the model performing poorly on new data, even if it may have high accuracy and performance on the initial training data.
When data scientists use machine learning models for making predictions, they first train the model on a known data set. Then, based on this information, the model tries to predict outcomes for new data sets.
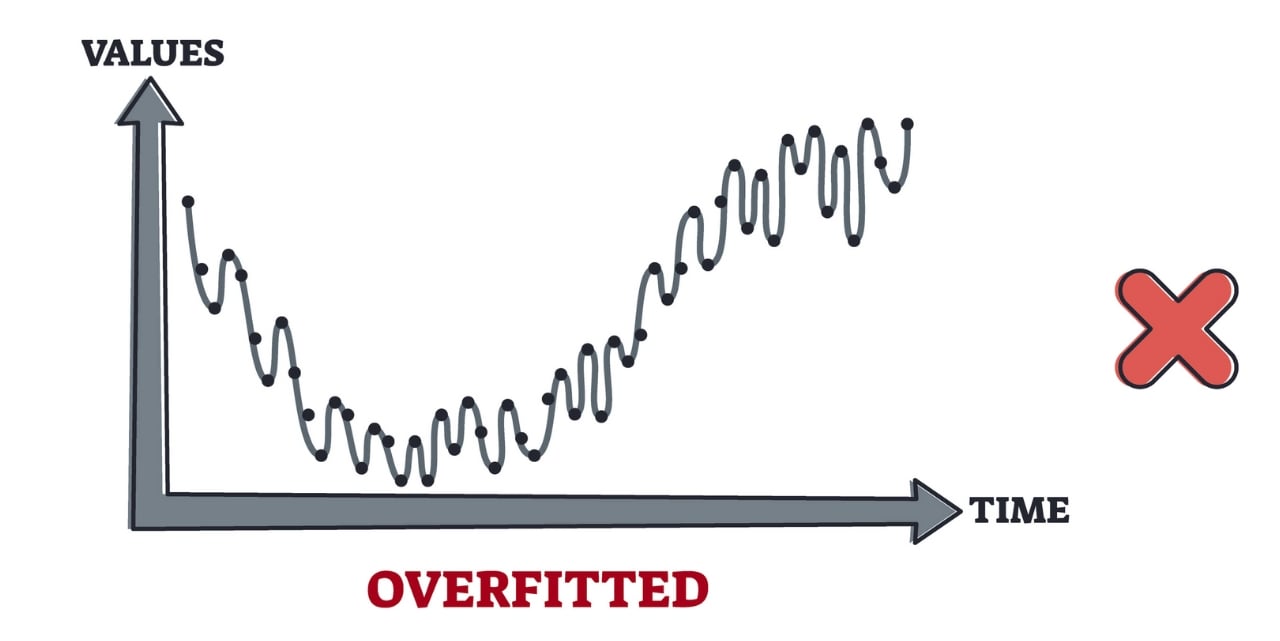
Overfit models can memorize too much of the data they’re trained on, including the noise and outliers they contain. This results in the model making inaccurate predictions and being unable to perform well for all types of new data beyond the initial data they’re trained on.
Why does overfitting happen?
Overfitting happens when the model focuses too much on the specifics of the training data and doesn't learn the underlying patterns that are relevant to new, unseen data. This leads to a model that performs well on the training data but poorly on new data.
There are several reasons why this can happen during the training process. Some of the most common culprits include:

When Ransomware Hits AI R&D
Novo Nordisk breach shows AI-driven drug pipelines are now core extortion leverage, forcing boards to rethink IP, data and resilience strategies.
1. Small training data
When the training data is too small, it may not represent the full range of possible data points. This means the model focuses on the specific examples it has seen instead of learning general patterns, leading to an overfit model.
Imagine trying to learn about all birds by only looking at pictures of pigeons. You might become very good at identifying pigeons, but you wouldn't be able to recognize other types of birds. This is exactly what happens with overfit models.
2. Noisy training data
If the training data contains a lot of noise or irrelevant information, the model can learn this noise and make inaccurate predictions on new data.
This is like trying to learn a language from someone who constantly mumbles and makes mistakes. You might end up learning the mistakes along with the correct words.
3. Complex models
Using a model that is too complex for the task can lead to overfitting. Complex models have more parameters and freedom to learn the data, which can lead them to pick up on irrelevant details and noise instead of focusing on the underlying patterns.
Nvidia's China Chip Gamble
Export-limited H200 variants, Chinese AI demand and state-backed fabs are reshaping data center silicon power in a contested market.

4. Overtraining
Training the model for too long on the same data can also lead to overfitting. As the model is exposed to the training data repeatedly, it starts to memorize the specific examples instead of learning generalizable patterns.
How can you detect overfitting?
The best way to detect overfitting before deploying an ML model is by testing the model on more data with more representation of possible input data values and types. You can use part of this training data as validation data to check for overfitting.
In most cases, if the model performs significantly better on the training set than on the validation set, it's likely overfitting.
Another way to detect overfitting is by plotting the model's performance (e.g., accuracy, loss) on both the training and validation sets as training progresses. In overfitting, the training performance will continue to improve, while the validation performance will reach a peak and then start to decline.
You can also Apply regularization techniques like L1 or L2 to help reduce the complexity of the model and prevent overfitting. If adding regularization significantly improves the model's performance on the validation set, it suggests that the original model was overfitting.
Two-Speed AI Startup Economy
How concentrated AI investment, fragile exits and ecosystem dependence on single funders can turn startup partners into hidden enterprise risk.
Examples of overfitting
Overfitting can occur in any machine learning task where the model becomes too focused on the specifics of the training data and fails to generalize well to new, unseen data. Here are some examples to show what this could look like in an ML model:
1. Bias towards a specific pattern
Imagine you train a model to predict a student's academic performance based on factors like past grades, test scores, and attendance. If the training data is biased towards a specific demographic or school, the model might learn patterns specific to that group and perform poorly on students from other backgrounds.
This is overfitting because the model is memorizing the specific characteristics of the training data instead of learning generalizable patterns about student performance.
2. Difficulty classifying images
A model trained to classify images of cats and dogs might overfit if the training data contains mostly pictures of cats in specific poses or environments. The model might then struggle to identify cats in new poses or backgrounds, even though it performed well on the training set.
When Model Choice Drives Value
Why enterprises must align ML models with business questions, data realities and governance to turn pilots into durable production value.

3. Incorrect Spam filtering
A spam filter trained on a specific set of spam emails might overfit to the language and formatting used in those emails. This could lead to the filter incorrectly classifying legitimate emails as spam if they use similar language or formatting.
4. Inaccurate predictions
A model trained to predict stock prices might overfit if the training data only covers a short period of time or specific market conditions. The model might then be unable to accurately predict prices in different market conditions or longer time horizons.
5. Misrepresentation
A model trained to analyze the sentiment of text might overfit if the training data contains mostly positive or negative reviews. This could lead to the model misinterpreting the sentiment of neutral or mixed reviews.
Overfitting vs Underfitting
Underfitting is another type of error that occurs when the model cannot determine a meaningful relationship between the input and output data.
Unlike overfitting where the model becomes too adapted to training data, overfitting happens when a model is too simple and cannot capture the underlying relationships in the data.
The key difference between overfit and underfit models is that overfit models only perform badly on new data, while underfit models give inaccurate results for both the training data and test set.
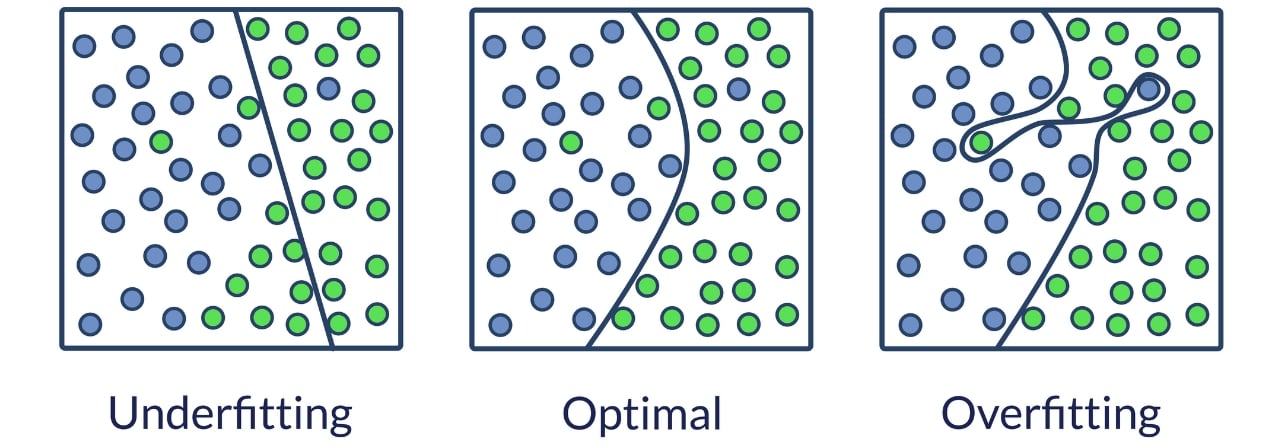
Underfit models experience high bias, giving inaccurate results for both the training data and test set. Meanwhile. Overfit models, however, experience high variance and give accurate results for the training set but not for the test set.
Data scientists try to find the right balance between model complexity and data size to avoid both overfitting and underfitting, ultimately leading to a model that generalizes well to unseen data and makes accurate predictions.
When a model is well-fitted, it can quickly establish the dominant trend for seen and unseen data sets and perform well on any dataset it’s presented with.
Preventing Overfitting
You can prevent overfitting by diversifying and scaling your training data set or by using some of the data-related and model-related techniques below to improve the fit of your model:
Data-related techniques:
- Increase training data size. The more data your model is exposed to, the less likely it is to overfit to specific examples. You can combine predictions from multiple models to create better training data and less overfit models.
- Data augmentation. If increasing the data size is difficult, you can artificially create new data points through techniques like image transformations (e.g., flipping, rotating) or adding noise. You can also divide your data into multiple folds and train the model on different combinations of folds. This helps to evaluate the model's generalizability and can help identify overfitting.
- Feature selection. Analyze your features and remove irrelevant or redundant ones that might contribute to overfitting.
Model-related techniques:
- Regularization. Techniques like L1 and L2 regularization penalize complex models, discouraging them from learning the noise in the data.
- Early stopping. Monitor the model's performance on a validation set during training. Stop training when the performance on the validation set starts to decline, preventing the model from memorizing noise.
- Dropout. This technique randomly "drops out" neurons during training, forcing the model to learn more robust features and reducing its reliance on individual neurons.
- Model complexity. Choose a model complexity that is appropriate for the task. Avoid using overly complex models, as they are more prone to overfitting.





Comments ( 0 )