
Businesses are responsible for more data than ever, however, over 70% of this data is left unused due to it being so difficult to organize- that’s where data warehouse tools come in.
Data warehouse tools are applications or platforms that streamline the entire data warehousing process. Choosing the right data warehouse tool depends on factors like the volume and variety of data, budget, technical expertise, and desired functionalities.

What is a data warehouse?
A data warehouse is a central location where businesses store information for analysis purposes.
The often large archive gathers data from multiple sources within a company such as sales figures, customer information, or website traffic.
This data is then organized and formatted in a way that makes it easy for analysts to identify trends and patterns.
Data warehouses are different from regular databases. They typically hold historical data to allow users to see how things have changed over time.
Data warehouses are designed for analysis, so they are optimized for complex queries and reports.
Data in a warehouse is usually cleansed and transformed to ensure consistency and accuracy.
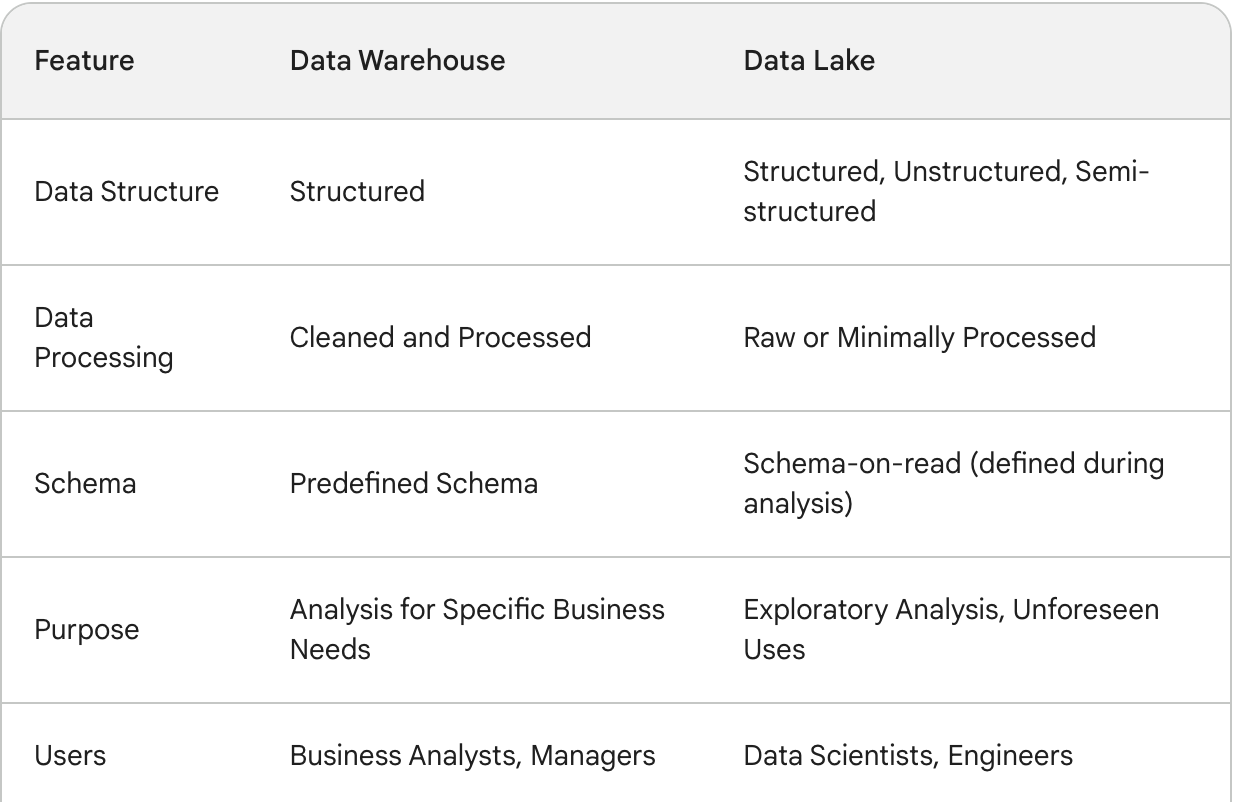
Data lake vs data warehouse
A data lake offers more comprehensive storage than a data warehouse. A data lake can hold any type of data, including raw, unstructured data like social media posts, sensor readings, or video files.
In a data lake structure is applied when the data is analyzed, whereas in a data warehouse structure is applied when it is stored.
The best data warehouse tools
Choosing the right data warehouse tool depends on factors like the volume and variety of data, budget, technical expertise, and desired functionalities.
In this article, we’re counting down the top ten data warehouse tools that streamline the entire data warehousing process.




Comments ( 0 )