










Tech Article
today
Ethical AI: Balancing Innovation with Responsibility in Business Strategy


Organizations today struggle with managing an increasing volume and variety of data spread across disparate systems.
This means that too much valuable data often goes unused. In fact, according to Seagate, 68% of organizational data is left untapped, meaning that not all desirable data is saved to begin with and there are difficulties accessing the data that does get stored.
To succeed in today’s data-driven world, such waste is unacceptable. So what do successful companies do to prevent a great deal of their business currency from stagnating away in forgotten data pools?
Well, many turn to data fabric and data mesh – two data architectures that integrate data from various pipelines and cloud environments. But while both data fabric and data mesh aim to improve data accessibility and usability, the way they do so is entirely different.
This article explores the key differences between data fabric vs data mesh, delving into how each architecture works to find out which is best for your business.
Data fabric is an architectural approach and set of tools designed to unify, integrate, and manage data across various sources and locations within an organization. It acts as a data management layer that sits on top of disparate systems, providing a single point of access and control for users.
Data fabric has a centralized integration layer, allowing it to create a virtualized layer that abstracts the complexity of underlying data storage. Users can access data from various sources (databases, applications, cloud storage) through a single interface, regardless of the physical location or format.

The architecture also integrates data from various sources like databases, cloud storage, applications, and even edge devices. This may involve data pipelines, APIs, and standardized protocols to automate data movement and transformation between systems.
Data fabric facilitates centralized data governance too. A central team can define and enforce data security, privacy, and quality standards across the organization. This ensures consistent data access and minimizes the risk of errors or unauthorized use.
Data fabric acts as a single point of entry for users to discover and retrieve data. It eliminates the need to navigate through disparate data sources and simplifies the data access process. This is achieved through a virtualized layer that sits on top of your physical data storage, presenting a unified view of all data assets.
Data fabric excels at integrating data from various sources. It utilizes connectors and adapters to seamlessly pull data from databases, data warehouses, data lakes, cloud storage, applications, and even Internet of things (IoT) devices.
Data fabric also automates many data management tasks, including data movement between systems, data transformation processes, and data quality checks. This automation frees up IT resources and improves overall efficiency.
Raw data is rarely usable in its original form. Data fabric employs a variety of data transformation techniques to clean, standardize, and enrich the ingested data. This might involve removing duplicates, correcting errors, converting formats, and enriching data with additional context. Additionally, data fabric incorporates data quality checks to ensure data accuracy and consistency throughout the platform.
A data catalog is a cornerstone of the data fabric. It acts as a detailed registry for all data assets within the system. The catalog stores information about data location, format, schema, lineage (history of transformations), and access control information. This allows users to easily discover relevant data sets and understand their characteristics.
Data fabric facilitates centralized data governance. A dedicated team can establish and enforce data quality standards, security policies, and access control rules within the data catalog. This ensures consistent data quality, minimizes the risk of unauthorized access, and helps organizations comply with data privacy regulations.
Data fabric empowers users with self-service capabilities. Users can explore the data catalog, discover relevant datasets, and initiate queries or data analysis tasks without relying on IT teams for every request. This fosters a data-driven culture within the organization and allows users to extract valuable insights from data more readily.
While not always a core feature, some data fabrics are incorporating advanced analytics and machine learning (ML) capabilities. ML algorithms can be used for data discovery within the catalog, suggest data quality improvements, automate data transformation processes, and even generate insights from data. This further enhances the intelligence and efficiency of data fabric.
Data fabric is designed to be scalable and adapt to evolving data needs. It can accommodate the addition of new data sources and users as your organization grows. Additionally, data fabric offers a degree of flexibility, allowing for customization to fit the specific data management requirements of your organization
A data mesh is a sociotechnical approach to building a decentralized data architecture. It emphasizes domain-oriented, self-serve design principles for data management, borrowing heavily from concepts like Domain-Driven Design (DDD) and Team Topologies.
With data mesh, data ownership shifts from a central IT team to the business domain that produces it (e.g., marketing, finance, sales). Domain experts inherently understand their data best and are empowered to manage it effectively based on their specific needs.
 The organization provides a platform that allows domain teams to easily store, process, and access their data. This platform could include data lakes, APIs, and data governance tools, enabling self-service, central IT is freed to focus on broader infrastructure and architecture concerns.
The organization provides a platform that allows domain teams to easily store, process, and access their data. This platform could include data lakes, APIs, and data governance tools, enabling self-service, central IT is freed to focus on broader infrastructure and architecture concerns.
Domain teams are also encouraged to think of their data as a product that can be consumed by other parts of the organization. This fosters a mindset of data quality, documentation, and ease of use. Data products are well-defined with clear ownership and service-level agreements (SLAs).
A key aspect of the data mesh is facilitating seamless data sharing across domains. Standardized APIs and data contracts are crucial elements that ensure consistent data formats and easy integration between different data products.
This is the core principle of a data mesh. Unlike traditional centralized models where a central IT team manages all data, data ownership in a mesh shifts to the business domains (marketing, finance, sales, etc.) that generate it. Domain teams understand their data best and are empowered to manage it effectively based on their specific needs.
The organization provides a platform that allows domain teams to store, process, and access their data independently. This platform could include data lakes, APIs, data pipelines, and data governance tools. By enabling self-service, central IT is freed to focus on broader infrastructure and architecture concerns, while domain teams gain agility and speed in their data analysis.
Domain teams are encouraged to treat their data as a well-defined product that can be consumed by other parts of the organization. This fosters a mindset of data quality, clear documentation, and ease of use. Data products have clear ownership, service-level agreements (SLAs) that define expectations, and well-documented APIs for access.
Seamless data sharing across domains is crucial in a data mesh. Standardized APIs and data contracts are essential elements that ensure consistent data formats and easy integration between different data products. This allows for efficient consumption and reuse of data across the organization.
While ownership is decentralized with data mesh, data governance is still important. A central governance framework establishes guidelines for data security, privacy, consistency, and quality across the mesh. This ensures the overall integrity and trustworthiness of the data ecosystem.
The ability to monitor and observe the health of the data mesh is crucial. This includes data pipelines, data quality metrics, and API performance. Monitoring allows for proactive identification and resolution of issues, ensuring the smooth flow of data within the mesh.
The decentralized nature of the data mesh makes it highly scalable. As the organization grows and new data sources emerge, domain teams can readily integrate them into the mesh without impacting existing data products. This allows the data architecture to adapt and evolve alongside the business.
The key difference between data fabric and data mesh is that data fabric provides a centralized view of data while data mesh provides a decentralized one.
Data fabric focuses on creating a single, unified data layer on top of distributed data sources, while data mesh uses a decentralized approach where data ownership and management are distributed to domain-specific teams within the organization.
Data fabric is primarily used to tackle data integration challenges. It aims to provide a consistent view of data across the organization, regardless of its physical location or format.
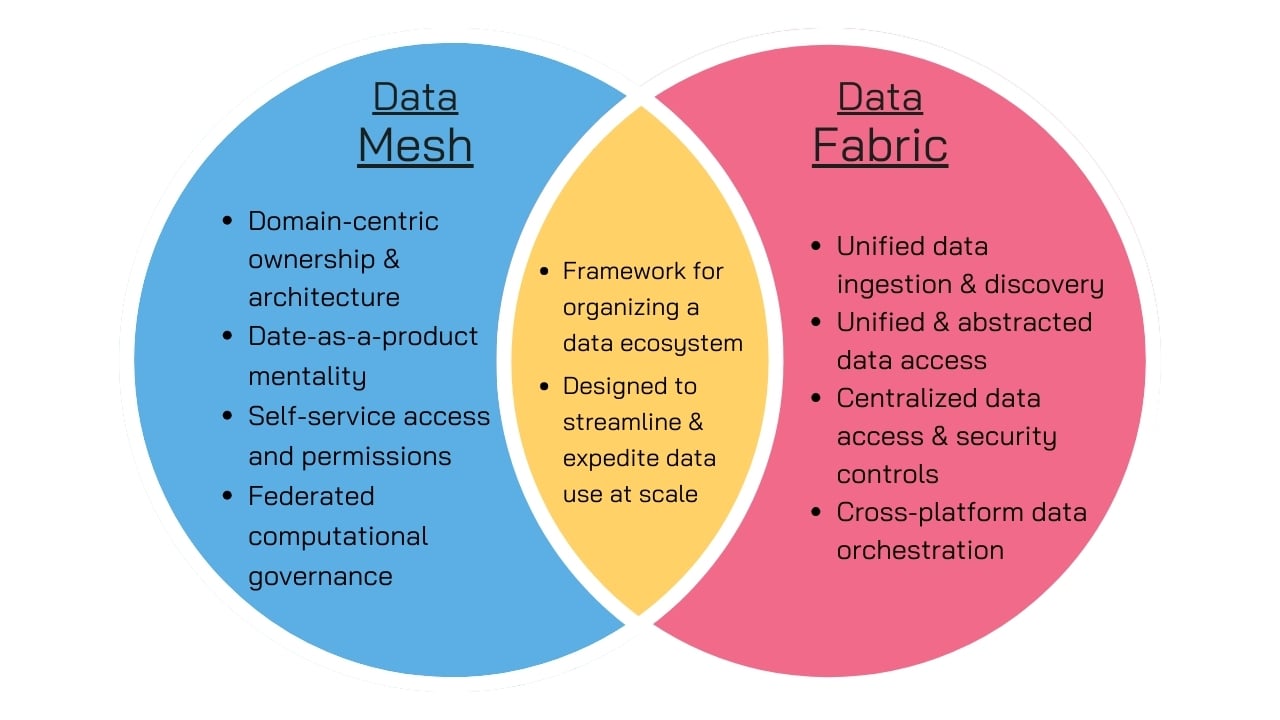
Data mesh, however, places more emphasis on data as a product and domain-oriented data ownership. It encourages teams to treat their data as a valuable asset to be shared and consumed by others within the organization.
Data Fabric also often involves implementing specific technologies like data virtualization tools, API gateways, and data governance platforms. It's a more technology-driven approach.
And while data mesh might leverage some technologies, it's more about a cultural shift and organizational change, and its success hinges on establishing clear data ownership, self-service capabilities, and standardized data practices.
Choosing between data fabric vs data mesh depends on what problem you’re trying to solve. A data fabric is a good fit for organizations struggling with data silos and fragmented data sources, while a data mesh is ideal for organizations with diverse data domains that require autonomy and faster data delivery.
Data fabric and data mesh can also be complementary, so you can use both. A data fabric can act as the underlying infrastructure for a data mesh.
It can provide a unified data layer for accessing and integrating data products created by domain teams in the data mesh.












